上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司顶顶AI助手是当前AI应用赛道中备受关注的一款智能助手产品。很多人每天都在使用这类AI助手,却对其背后的技术原理知之甚少,只会用、不懂原理、概念易混淆、面试答不出,这是许多技术学习者的共同痛点。本文将围绕顶顶AI助手所代表的新一代智能助手技术体系,由浅入深讲解其核心技术概念、运行机制和底层原理,并提供可运行的代码示例和面试要点,帮助读者建立从“会用”到“懂原理”的完整知识链路。
本文阅读提示:适合技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师,兼顾技术科普与原理讲解。

一、痛点切入:为什么需要AI助手?
在AI助手出现之前,传统的自动化工具通常采用规则驱动模式——用户需要手动配置、编写脚本或点击操作才能完成特定任务。
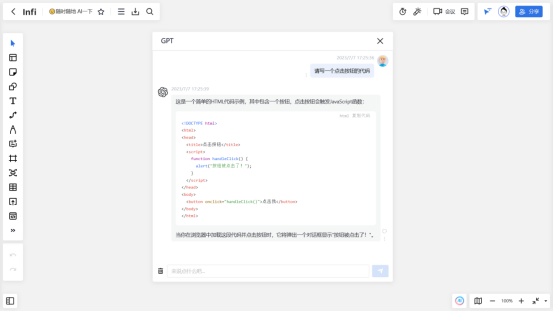
旧有实现方式的伪代码示例:
传统规则式任务处理(伪代码) def handle_user_query(user_input): if "天气" in user_input: city = extract_city(user_input) return call_weather_api(city) elif "提醒" in user_input: time, task = extract_reminder(user_input) return save_to_calendar(time, task) else: return "无法理解您的指令"
这种方式的缺陷很明显:
耦合性高:每一种意图都需要预先编码规则,新增功能需修改核心逻辑
扩展性差:无法处理未预定义的自然语言表达
维护成本高:规则数量激增后,逻辑冲突和遗漏问题频发
缺乏学习能力:无法从用户交互中优化自身表现
AI助手的设计初衷正是为了解决这些问题——通过大语言模型(Large Language Model,LLM)的自然语言理解能力,让系统能够“听懂”用户的真实意图,而不是机械匹配关键词。
📌 一句话理解:传统规则系统是“程序员告诉机器做什么”,AI助手是“机器自己理解用户要什么”。
二、核心概念讲解:大语言模型(LLM)
标准定义
大语言模型(LLM) 是指基于海量文本数据预训练、参数量达数十亿甚至数千亿的深度学习模型,具备自然语言理解、生成和推理能力。
拆解关键词
大:参数量巨大,典型规模从数十亿到万亿级别
语言:以自然语言为核心处理对象
模型:本质是一个深度学习神经网络
生活化类比
可以把LLM理解为一个“读过万卷书的学霸”:
这个学霸在“上岗”之前,读遍了互联网上的海量文本、书籍、代码和知识。当你向顶顶AI助手提问时,它不会死记硬背答案,而是像学霸一样——理解问题、调动知识、组织语言来回答你。它知道你问“明天去北京”时,潜台词是“帮我查天气、规划路线、订酒店”,而不是真的只想讨论北京这座城市-5。
核心价值
LLM让AI助手具备了三个关键能力:
理解力:理解口语化、模糊甚至带错别字的自然语言
推理力:在多轮对话中保持逻辑连贯,完成复杂问题拆解
生成力:输出符合语境、语法正确、风格多样的内容
三、关联概念讲解:AI Agent(智能体)
标准定义
AI Agent(人工智能智能体) 是一类具备环境感知、规划能力、工具调用与行动闭环的目标导向系统,能够自主完成复杂任务-7。
LLM与Agent的关系
这是学习中最容易混淆的一对概念。一个形象的区分方式:
| 层级 | 核心能力 | 定位 |
|---|---|---|
| LLM(大模型) | 理解+生成文本 | “大脑”——超级语言引擎 |
| AI助手 | LLM + 交互界面 + 记忆管理 | “会说话的大脑” |
| AI Agent | LLM + 规划+工具调用+行动闭环 | “会行动的智能体” |
📌 简单比喻:LLM是“会思考的脑”,AI助手是“会说话的脑”,而智能体是“会干活的全人”-4。
智能体的四大核心特征
一个完整的AI Agent必须具备-4:
自主目标分解:接到高层指令后,自行拆解为可执行的子任务序列
工具调用能力:调用引擎、API、代码执行器等外部工具
闭环行动能力:形成“感知→规划→行动→反馈→修正”的完整循环
持久记忆与状态管理:跨会话保持上下文贯通
一句话区分
LLM:能回答问题,但止步于“说”
AI助手(如顶顶AI助手):能多轮对话、记住上下文,但仍以“对话”为核心交互
AI Agent:能真的去执行操作——订票、发邮件、调API、写代码
四、概念关系总结
┌─────────────────────────────────────────────┐ │ AI Agent │ │ ┌─────────────────────────────────────────┐ │ │ │ AI 助手 │ │ │ │ ┌───────────────────────────────────┐ │ │ │ │ │ LLM │ │ │ │ │ │ (语言理解 + 文本生成) │ │ │ │ │ └───────────────────────────────────┘ │ │ │ └─────────────────────────────────────────┘ │ └─────────────────────────────────────────────┘
记忆口诀:LLM是内核,助手是入口,Agent是执行者。
顶顶AI助手属于AI助手这一层级——它以LLM为核心驱动,通过交互界面与记忆管理服务用户,但在技术演进中正在逐步融入Agent能力。
五、代码示例:从零实现一个极简AI助手核心
下面是一个最简化的示例,演示LLM如何解析用户意图并调用对应工具。
import json 模拟LLM的意图识别(实际场景中由真实大模型完成) def llm_understand(user_input): """模拟LLM将用户输入解析为意图和参数""" if "天气" in user_input: return {"intent": "weather", "params": {"city": extract_city(user_input)}} elif "提醒" in user_input: return {"intent": "reminder", "params": {"task": user_input}} else: return {"intent": "chat", "params": {"message": user_input}} 工具函数——相当于顶顶AI助手的“手脚” def call_weather_api(city): return f"{city}明天晴,温度18-26℃" def set_reminder(task): return f"已设置提醒:{task}" def generate_reply(message): return f"(AI回复)关于「{message}」,这是一个有趣的问题..." 核心调度器——相当于顶顶AI助手的“大脑” def process_user_input(user_input): 1. LLM理解意图 parsed = llm_understand(user_input) 2. 根据意图分发给对应工具 if parsed["intent"] == "weather": result = call_weather_api(parsed["params"]["city"]) elif parsed["intent"] == "reminder": result = set_reminder(parsed["params"]["task"]) else: result = generate_reply(parsed["params"]["message"]) 3. 返回结果 return result 运行示例 print(process_user_input("明天北京天气怎么样")) 输出:北京明天晴,温度18-26℃ print(process_user_input("提醒我下午开会")) 输出:已设置提醒:提醒我下午开会
执行流程说明:
用户输入自然语言 → 顶顶AI助手接收
LLM层解析意图(理解“用户想做什么”)
根据意图调用对应工具函数(执行具体操作)
返回结果给用户
💡 实际产品中的差异:真实场景中,顶顶AI助手背后是真实的LLM(如数百亿参数的大模型),意图识别不是靠关键词匹配,而是靠模型在海量数据中习得的语义理解能力。
六、底层原理:支撑AI助手的三大核心技术
顶顶AI助手这类产品之所以“懂你”,本质上是三大核心技术的协同发力-5:
技术一:LLM——AI助手的“大脑”
这是整个系统的核心。LLM通过Transformer架构和自注意力机制,能够捕捉词语之间的长距离依赖关系,实现对用户输入的理解和推理。顶顶AI助手背后的大模型在预训练阶段学习了海量文本,使其具备了通用的语言能力-5。
技术二:RAG检索增强生成——“实时查资料的小助手”
纯LLM的知识截止于训练数据的时间点。RAG(Retrieval-Augmented Generation,检索增强生成) 技术给LLM配了一个“随时能联网查资料”的工具。当用户问“2026年最新的某某事件”时,RAG会先检索最新数据,再让LLM基于检索结果生成答案,让AI助手摆脱“知识过时”的局限-5。
技术三:工具调用(Function Calling)——“手脚”
光会理解还不够,能把事情落地才是实用的助手。工具调用技术让LLM能够调用各种外部API和工具完成具体任务——查天气、订票、发邮件、写代码,这些都是靠工具调用实现的-5。
💡 底层依赖:这三项技术共同依赖于深度学习框架(PyTorch/TensorFlow)、分布式计算基础设施、以及大规模高质量训练数据。
七、市场定位与行业趋势(2026年4月)
截至2026年4月,AI应用市场呈现出清晰的格局。2026年1月AI应用榜单显示,原生AI赛道中AI助手类应用已成为绝对主力,抖音旗下豆包以显著优势位居榜首,腾讯元宝以47.5%的复合增长率成为头部中增长最快的产品,AI助手类应用包揽了原生AI赛道前四名-13。
行业趋势要点:
市场呈现头部集中化特征,大厂旗下产品牢牢占据核心席位
赛道差异化显著,AI助手、智能创作、AI教育成为三大增长动力
中小厂商在垂直赛道仍有机会崭露头角
智能体(Agent)被普遍认为是下一阶段的增长点-13
价格趋势:2026年以来,国内大模型厂商普遍调整了定价策略,部分API价格有所上调,同时分层定价策略更加成熟,反映出市场从“补贴抢份额”向“价值定价”的转变-14。
八、高频面试题与参考答案
Q1:LLM和AI Agent有什么区别?
参考答案:
LLM是一个被动响应的语言模型,核心功能是“理解+生成文本”
AI Agent在LLM基础上增加了规划能力、工具调用和行动闭环,能自主完成复杂任务
比喻:LLM是大脑,Agent是“大脑+手脚”的完整系统
踩分点:点明“被动vs主动”的本质差异 + 举例说明Agent多了哪些能力。
Q2:AI助手是如何实现“多轮对话记忆”的?
参考答案:
通过上下文窗口(Context Window) 存储最近几轮对话
配合会话管理(Session Management) 为每个用户维护独立对话历史
进阶方案使用向量数据库做长期记忆存储,实现跨会话回忆
踩分点:短期记忆(上下文窗口) + 长期记忆(向量检索)两层机制。
Q3:RAG和Fine-tuning在AI助手中分别解决什么问题?
参考答案:
RAG:动态检索外部知识,适合需要最新信息、知识频繁更新的场景,如实时新闻、产品活动
Fine-tuning:让模型学习特定领域的表达方式和行为模式,适合风格固定、知识相对稳定的场景
实践中两者常结合使用:Fine-tuning定风格和基础能力,RAG补充时效性信息
踩分点:区分“动态检索”与“静态训练” + 适用场景 + 结合使用策略。
Q4:AI助手的工具调用是如何保证安全性的?
参考答案:
权限控制:每类工具定义明确的操作权限边界
参数校验:LLM生成的参数经过验证后再执行
人工介入机制:高风险操作(如支付、删除数据)必须经过用户确认
输出边界约束:不允许AI助手“自由行动”,所有工具调用都有明确的输入输出边界-7
踩分点:从“权限→校验→确认→约束”四个层面回答,体现系统化思维。
九、总结与预告
核心知识点回顾
| 概念 | 一句话理解 | 关键特征 |
|---|---|---|
| LLM | 理解+生成文本的大脑 | 被动响应、通用能力 |
| AI助手 | LLM + 交互界面 + 记忆 | 多轮对话、个性化 |
| AI Agent | 助手 + 规划 + 工具 + 行动 | 自主执行、闭环反馈 |
重点与易错点
易混淆:不要把LLM和Agent混为一谈——二者是“能力”与“系统”的关系,LLM是Agent的核心组件,但Agent不止LLM
易忽略:RAG和工具调用是让AI助手“好用”的关键,很多初学者只关注LLM本身,却忽略了这两层技术
易错:工具调用≠API调用——工具调用是由LLM自主决策的,而传统API调用是硬编码的
进阶内容预告
下一篇文章将深入讲解AI Agent的工程化落地,包括:
Agent的四阶段开发范式(场景定义→架构设计→知识工程→评估测试)
ReAct推理模式的代码实现
从AI助手到Agent的完整演进路径
📌 欢迎持续关注本系列,从“会用”到“懂原理”,再到“能落地”,一步步构建完整的AI技术知识体系。