上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司西语助手AI,这款由中国开发者专为西语学习者打造的教育软件,已从传统的电子词典进化为融合大语言模型技术的智能学习平台-。它集成了AI文本翻译、智能写作批改、多场景口语对话等功能,正深刻改变着语言学习的方式-。
许多语言学习者在面对西班牙语时,普遍感到迷茫——单词记不住、变位分不清、写作无处改、口语不敢说。传统词典软件只能告诉你“这是什么词”,却无法解答“这个词怎么写才对”“这个句子哪里有问题”。西语助手AI的出现,正是为了解决这些痛点,让学习者不仅“查得准”,更能“学得透”。
一、痛点切入:为什么需要西语助手AI
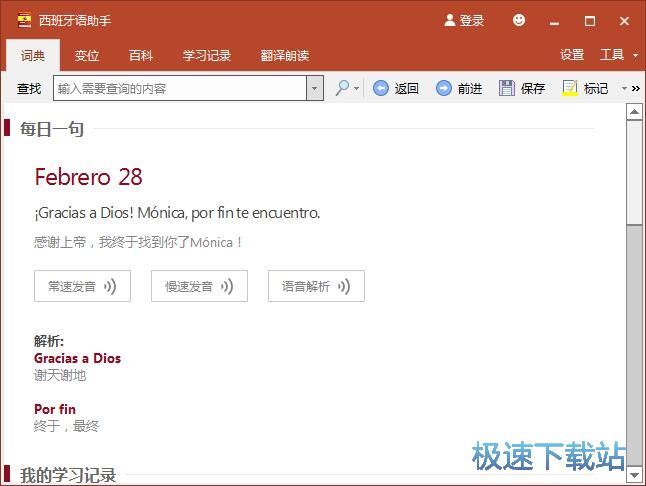
传统西语学习工具的局限很明显。以西语动词变位为例,西班牙语有17种时态,每个动词在不同人称下有不同的变位形式,光靠死记硬背效率极低-4。传统电子词典只能展示变位表,却无法根据上下文自动判断应该使用哪种时态,更无法针对性地生成例句帮助理解和记忆。
西语助手AI的解决思路:将大语言模型的理解能力与词典数据相结合,让AI不仅能“查”,更能“判”和“教”。以西语助手AI问答功能为例,用户输入一个句子后,AI能分析其语法结构,判断时态使用是否正确,并给出修正建议-。
“传统查词是‘点对点’,AI辅助学习是‘面面俱到’。”——西语助手AI让学习从被动接收转向主动交互。
二、核心概念讲解:AI Agent(智能体)
AI Agent(人工智能智能体,AI智能体) 是指能够感知环境、自主决策并执行行动的智能系统。它是2026年AI领域最核心的技术演进方向-。
用一个生活化的类比:传统词典App就像一本纸质词典,你需要自己去翻、自己去理解;而西语助手AI中的AI Agent,就像一个24小时在线的私人西语家教——它能听懂你的问题,记住你的学习进度,规划适合你的学习路径,调用各种工具(词典、变位表、例句库)来帮你解决问题。
AI Agent的核心能力由感知、大脑、行动和记忆四大模块协同支撑-。其中“大脑”以大语言模型为核心,负责理解用户意图并拆解任务;“行动”模块调用外部工具执行具体操作;“记忆”模块通过短期与长期记忆优化服务体验-。
西语助手AI正是基于这一技术架构,将词典查询、变位检索、例句翻译等传统功能与AI问答、智能批改等新能力有机整合,形成了一个完整的智能学习闭环。
三、关联概念讲解:大语言模型(LLM)
大语言模型(Large Language Model,LLM) 是一种基于海量文本数据训练而成的深度学习模型,能够理解、生成和处理自然语言。
LLM与AI Agent的关系:LLM是AI Agent的“大脑”,AI Agent是LLM的“身体”。如果说LLM是一个知识渊博但只会坐在那里回答问题的“理论家”,那么AI Agent就是给这个理论家装上了“手”和“脚”,让它能够真正去“做事”——调用工具、执行操作、完成复杂任务-14。
举个例子:单纯使用LLM,你可以问它“ser和estar的区别”,它会给你一个理论解释。但在西语助手AI中,基于AI Agent架构,系统可以主动调用词典模块展示两个动词的完整变位表,调用例句库生成对比例句,甚至可以调用AI问答功能针对你的具体使用场景给出个性化建议。这就是“LLM + 工具调用”带来的质变。
西语助手AI在2025年引入了AI翻译引擎、写作辅助系统、智能纠错技术等AI功能,其AI翻译引擎基于神经网络技术,能够处理复杂长句和专业术语-4。2026年初发布的v26.2.0版本,进一步引入了基于AI技术的主题写作、批改纠错等核心功能-。
四、概念关系与区别总结
| 维度 | LLM(大语言模型) | AI Agent(智能体) |
|---|---|---|
| 定位 | 核心引擎/大脑 | 完整系统/身体 |
| 核心能力 | 理解、生成语言 | 感知、决策、行动、记忆 |
| 交互方式 | 单次问答 | 多轮闭环任务 |
| 工具调用 | 不支持 | 支持调用外部API |
| 记忆能力 | 有限上下文 | 短期+长期记忆 |
一句话总结:LLM是AI Agent的核心能力来源,AI Agent是LLM的落地形态——前者解决“懂不懂”,后者解决“能不能”。
五、代码/流程示例演示
下面通过一个简化的Python示例,展示西语助手AI背后的AI Agent工作流程。假设我们要实现一个“西语AI学习助手”,它能够根据用户输入的问题,自动判断是否需要查词典、查变位或做语法分析。
简化版AI Agent示例 - 西语学习助手 import json from typing import Dict, List class SpanishLearningAgent: """ 西语AI学习助手智能体 核心架构:感知 -> 决策 -> 行动 -> 记忆 四步闭环 """ def __init__(self): self.memory = [] 短期记忆:存储本轮对话 self.tools = { "search_dictionary": self.search_dictionary, "get_conjugation": self.get_conjugation, "grammar_check": self.grammar_check } def search_dictionary(self, word: str) -> str: """工具1:查词典""" 模拟调用西语助手的词典模块 return f"{word}的中文释义是..." def get_conjugation(self, verb: str, tense: str) -> str: """工具2:查动词变位""" 模拟调用变位表查询 return f"{verb}在{tense}时的变位为..." def grammar_check(self, sentence: str) -> str: """工具3:语法检查""" 模拟AI写作批改功能 return f"句子'{sentence}'的语法分析结果..." def decide_action(self, user_input: str) -> Dict: """决策模块:基于LLM判断用户意图""" 实际场景中,这里会调用LLM进行意图识别 这里简化为关键词匹配示例 if "什么意思" in user_input: return {"action": "search_dictionary", "params": {"word": user_input.split()[0]}} elif "变位" in user_input: return {"action": "get_conjugation", "params": {"verb": user_input.split()[0], "tense": "现在时"}} elif "写得对吗" in user_input: return {"action": "grammar_check", "params": {"sentence": user_input}} return {"action": None, "params": {}} def execute(self, user_input: str) -> str: """执行模块:感知-决策-行动-记忆闭环""" 1. 感知:接收用户输入 print(f"用户输入:{user_input}") 2. 决策:判断意图并选择工具 decision = self.decide_action(user_input) 3. 行动:调用对应工具 if decision["action"] and decision["action"] in self.tools: result = self.tools[decision["action"]](decision["params"]) else: result = "我不太理解您的问题,请重新描述。" 4. 记忆:保存到短期记忆 self.memory.append({"input": user_input, "action": decision["action"], "result": result}) return result 使用示例 agent = SpanishLearningAgent() 模拟用户交互 print(agent.execute("ser 什么意思")) 触发词典查询 print(agent.execute("hablar 现在时变位")) 触发变位查询
执行流程解读:
感知层:用户输入“ser 什么意思”
决策层:Agent识别出意图是“查词典”
行动层:调用词典工具,返回释义
记忆层:将本次交互存入短期记忆,为后续多轮对话提供上下文
这个极简示例展示了AI Agent的核心工作流程。在实际的西语助手AI中,这一流程由更复杂的神经网络模型驱动,支持多轮对话、上下文理解和个性化学习路径推荐。
六、底层原理与技术支撑
西语助手AI的技术底座主要依赖以下关键技术:
1. 大语言模型(LLM) :西语助手AI底层接入了大语言模型作为翻译和问答引擎,2025年的版本已支持导入DeepSeek作为大模型翻译引擎-5。LLM负责理解用户意图、生成自然语言回复、进行智能批改等核心功能。
2. 神经网络翻译引擎:西语助手AI的翻译功能基于神经网络技术,能够处理复杂长句和专业术语,相比传统的统计机器翻译,译文流畅度和准确性大幅提升-。
3. 智能批改系统:可识别拼写、语法、搭配等错误,并给出修正方案。这背后依赖语法解析器和大规模语料训练的语言模型-。
4. 向量检索与RAG(检索增强生成) :当用户查询生词或例句时,系统并非让LLM凭空生成,而是先从西语助手内置的权威词库中检索相关信息,再结合LLM生成个性化回复。这种方式既保证了信息的准确性,又保留了AI的灵活性。
这些底层技术共同支撑了西语助手AI的智能问答、智能写作批改、多场景口语对话等功能-。值得注意的是,西语助手AI已支持添加多种第三方AI翻译引擎,并可自定义翻译风格,体现了其开放的技术架构-5。
七、高频面试题与参考答案
面试题1:什么是AI Agent?它与传统大语言模型调用的核心区别是什么?
参考答案:
AI Agent(人工智能智能体)是指能够感知环境、自主决策并执行行动的智能系统。与传统LLM调用的核心区别有三点:
自主性:传统LLM是单次问答,每次独立;AI Agent具备长期任务规划能力,能自主拆解复杂目标为子任务-。
工具调用:LLM只能输出文本;AI Agent可以调用外部API(如词典、变位表、代码解释器),真正“动手做事”-14。
记忆机制:LLM只有有限的上下文窗口;AI Agent具备短期记忆(工作记忆)+长期记忆(外部存储),可支持长周期任务-15。
踩分点:务必说清楚“传统LLM是被动的对话工具,AI Agent是主动的任务执行者”这一核心差异。
面试题2:Agent架构中的感知-决策-行动-记忆四模块分别是什么?如何协同工作?
参考答案:
现代AI Agent依托四大模块构建“感知—决策—行动—记忆”的认知闭环:
感知模块:采集多源信息并结构化处理,理解用户输入和环境状态-。
大脑模块:以大语言模型为核心,理解意图、拆解任务、制定计划-。
行动模块:调用工具执行操作,如查询数据库、调用API等-。
记忆模块:通过短期记忆(缓存当前会话)与长期记忆(向量数据库)优化服务质量-。
协同流程:用户输入 → 感知模块解析 → 大脑模块决策规划 → 行动模块执行 → 结果写入记忆 → 反馈大脑进行下一轮决策。
踩分点:四模块缺一不可,要说出“闭环”二字,体现架构的完整性。
面试题3:Agent常见的失败场景有哪些?如何解决?
参考答案:
三种常见的失败场景及解法:
| 失败场景 | 原因 | 解法 |
|---|---|---|
| 工具调用失败 | LLM生成参数格式不对 | 参数校验+失败重试+人工兜底 |
| 上下文溢出 | 对话轮数过多 | 上下文压缩+定期摘要+滑动窗口 |
| 目标漂移 | 执行偏离原始目标 | 步骤目标对齐+定期反思+重新规划 |
踩分点:不只要列举问题,更要给出可落地的解决方案,体现实战经验。
面试题4:ReAct、CoT、ToT这些规划方法有何区别?如何选择?
参考答案:
CoT(思维链) :引导模型“一步步思考”,适合逻辑推理任务,如数学题。
ReAct(推理+行动) :边思考边行动,每步看结果再决策,适合需工具调用的场景-42。
ToT(思维树) :并行探索多条推理路径,效果好但Token消耗大,适合线下深度推理。
选择建议:日常问答用CoT,需工具调用的交互场景用ReAct,成本不敏感的高精度场景用ToT。
踩分点:必须说清三者的适用场景和成本差异,体现权衡思维。
八、结尾总结
本文围绕西语助手AI这一典型案例,系统梳理了AI Agent技术的核心概念、架构原理与实战应用。回顾全文的关键知识点:
西语助手AI已从传统词典进化为融合LLM的智能学习平台,覆盖查词、变位、翻译、批改、对话等全场景。
AI Agent = LLM + 规划 + 记忆 + 工具调用,这是2026年AI技术演进的核心公式。
感知-决策-行动-记忆四步闭环是AI Agent的标准架构。
大语言模型是大脑,AI Agent是完整身体——前者解决“懂不懂”,后者解决“能不能”。
面试中重点考察对Agent本质的理解、失败场景的处理能力、以及规划方法的取舍权衡。
易错点提醒:不要将AI Agent等同于大语言模型。LLM是组件,Agent是系统。在实际项目和技术面试中,区分清楚“是什么”和“能做什么”至关重要。
下一篇预告:我们将深入探讨如何基于LangChain框架从零构建一个AI Agent,涵盖环境配置、工具注册、多轮对话管理等实战内容,敬请期待。