上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司关键词:常见AI语音助手、技术架构深度拆解、面试高频题(ASR vs NLU),附代码
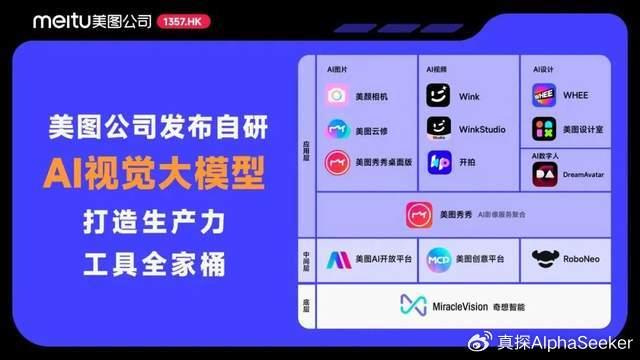
2026年4月10日,智能语音助手赛道正经历深度重构。全球市场2026年预计规模达96.2亿美元,同比增长33.5%-1。 Siri的功能推进跌宕起伏,小米小爱同学全面升级智能中枢,天猫精灵则深耕主动服务体验。 本文将以Siri、小爱同学、天猫精灵、豆包、Google Assistant等五大常见AI语音助手为切入点,深度剖析其技术架构演变、核心原理及面试高频考点。
一、技术痛点:语音交互从指令型到主动型的演进之困
早期语音助手实现方式基于“唤醒词触发—关键词匹配—预设任务执行”的简单范式。但这种方式存在三大硬伤:一是无法处理多轮对话的上下文,二是难以理解用户真正意图,三是缺乏对环境的感知能力。

以某电商客服场景为例:
传统关键词匹配方案(低效、易出错) class SimpleVoiceAssistant: def __init__(self): self.keywords = {"天气": "查询天气", "音乐": "播放音乐"} def process(self, user_input): for kw, action in self.keywords.items(): if kw in user_input: return action return "无法识别指令" 无法处理“帮我查一下明天杭州会不会下雨”这种复杂表达
这种实现方式缺乏上下文记忆,无法进行意图推理。根据行业数据,传统规则引擎的意图识别准确率仅60%~70% ,而基于Transformer架构的深度学习模型可将准确率提升至90%以上-52。
二、五大常见AI语音助手:2026年4月最新动态速览
2.1 Siri:坎坷的AI进化路
苹果Siri在2026年上半年的发展可谓一波三折。2026年1月,苹果与谷歌达成多年期合作协议,Gemini成为Apple Intelligence体系的重要技术支撑之一-11。3月,苹果被曝正在测试独立Siri应用及“Ask Siri”系统入口,计划于6月9日WWDC 2026正式亮相。新版Siri代号“Campo”,将支持语音与文本对话、访问备忘录与邮件等个人数据、检索开放网络信息,目标从传统语音助手转型为系统级AI智能体-12。
2.2 小米小爱同学:全面升级智能中枢
2026年4月3日,小米超级小爱完成V7.12重磅版本更新,新增记忆、日程管理、发现页、翻译及深度研究五大核心功能模块-23。记忆功能支持三指上滑手势快速触发,记忆进度实时同步至“小米超级岛”;深度研究功能支持自动生成网页版研究报告,可后台持续生成并同步至小米超级岛-23。小米汽车小爱同学还新增了手机遗落提醒功能-。
2.3 天猫精灵:深耕“主动智能”
阿里巴巴推出的天猫精灵已从单一“语音交互入口”演进为能够统筹全屋设备的 “空间智能大脑” ,甚至成为能够感知环境、理解意图、主动服务的“隐形管家”-30。最新版本搭载新一代AI引擎,语音识别准确率提升至98%,支持超过1000种智能家居设备的语音控制-34。全屋智能通过AI空间传感器实现“零交互”体验,用户无需说“开灯”“关窗帘”,系统便能根据人体位置、姿态变化自动调节环境-。
2.4 豆包手机助手:多模态新锐
字节跳动旗下的豆包手机助手以多模态交互能力和AI操作手机功能脱颖而出。用户可通过语音、侧边键或豆包Ola Friend耳机直接唤醒豆包,并在任意界面就屏幕内容进行提问,打破了传统语音助手仅依赖语音输入的单通道限制-。
2.5 Google Assistant:稳健迭代
作为Android生态的核心组件,Google Assistant持续优化其在多语言支持与跨设备协同方面的能力。2026年其整合了Gemini大模型能力,意图理解与上下文关联能力进一步强化。尤其值得关注的是,其on-device处理方案以隐私保护为优先,音频处理全在本地完成,无需上传云端-5。
三、核心概念一:自动语音识别(ASR)
3.1 标准定义
自动语音识别(Automatic Speech Recognition, ASR)是一种将人类语音信号转换为可编辑文本的技术,其核心目标是通过算法模型理解语音内容并生成对应的文字输出-。
3.2 生活化类比
可以这样理解:ASR就像一位速记员,当你说话时,他快速将你的语音“听写”成文字。这位速记员要处理口音、语速、背景噪音等各种复杂情况,并努力保证准确率。
3.3 技术原理拆解
现代ASR系统包含三大核心模块:
声学建模:分析语音信号的频谱特征,将其转化为音素或音节-41。传统方案采用GMM-HMM(高斯混合模型-隐马尔可夫模型)框架,在安静环境下准确率可达85%,但依赖专家设计特征,复杂场景性能受限-40。
语言建模:基于统计模型或神经网络预测词汇序列的概率。Transformer架构的引入彻底改变了ASR范式,其自注意力机制通过QKV矩阵计算实现长距离依赖建模-40。某主流云厂商的Conformer模型在LibriSpeech数据集上词错率(Word Error Rate, WER)已降至3.2%-40。
解码算法:结合声学模型与语言模型,通过动态规划(如Viterbi算法)或注意力机制生成最优文本结果-41。
四、核心概念二:自然语言理解(NLU)与对话管理
4.1 标准定义
自然语言理解(Natural Language Understanding, NLU)是语音助手理解用户真实意图的核心模块。它在ASR将语音转文字后登场,负责解析文本语义、识别用户意图并提取关键实体信息。对话管理(Dialog Management, DM)则负责维护对话状态、管理上下文并决定系统下一步行为-50。
4.2 ASR与NLU的关系
用一句话概括: ASR负责“听清”用户说了什么,NLU负责“听懂”用户想表达什么。 一个将语音转成文字,一个从文字中提取意图。
4.3 实现机制示例
ASR + NLU 完整处理流程示例 import speech_recognition as sr 假设使用科大讯飞或百度API进行意图解析 def voice_interaction_pipeline(): Step 1: ASR - 将语音转文字 recognizer = sr.Recognizer() with sr.Microphone() as source: print("请说话...") audio = recognizer.listen(source) try: text = recognizer.recognize_google(audio, language="zh-CN") print(f"ASR输出: {text}") Step 2: NLU - 解析意图 intent, entities = nlu_parse(text) print(f"意图识别: {intent}") print(f"提取实体: {entities}") return execute_intent(intent, entities) except Exception as e: return "识别失败"
基于Transformer架构的深度学习模型通过自注意力机制(Self-Attention) 实现上下文关联,意图识别准确率可达90%以上。例如,某行业头部方案支持200+细分意图识别,可覆盖电商售后、金融咨询等复杂场景的语义解析需求-52。采用智能体架构的企业客服效率提升可达47%-。
五、概念关系总结
| 维度 | 自动语音识别(ASR) | 自然语言理解(NLU) |
|---|---|---|
| 核心任务 | 将语音信号转化为文本 | 从文本中提取意图与实体 |
| 输入 | 音频波形/频谱特征 | 文本字符串 |
| 输出 | 文本序列 | 意图分类 + 实体列表 |
| 技术依赖 | 声学模型 + 语言模型 | Transformer + 预训练大模型 |
| 行业标杆准确率 | WER词错率可低至3.2% | 意图识别准确率可达90%+ |
一句话记忆:ASR让机器听清人话,NLU让机器听懂人话。
六、代码/流程示例:从语音输入到意图响应
6.1 完整处理流程架构
用户语音 → ASR(声学模型+语言模型)→ NLU(意图识别+实体提取)→ 对话管理 → TTS合成 → 用户响应6.2 现代智能语音助手核心处理流水线
现代语音机器人采用分层架构设计,典型处理流程包含-50:
音频采集与声学前端处理:通过深度学习降噪模型替代传统信号处理算法,在85dB背景噪音下仍可保持92%以上的唤醒率-50
语音识别(ASR) :将音频转化为文本
语义理解(NLU) :解析用户意图
对话管理(DM) :维护上下文状态
语音合成(TTS) :生成语音输出
6.3 代码示例
现代语音助手处理流水线示例(伪代码) class ModernVoiceAssistant: def __init__(self): self.asr_model = load_asr_model() 基于Transformer的ASR self.nlu_model = load_nlu_model() 基于预训练大模型的NLU self.dialog_memory = [] 多轮对话记忆 def process(self, audio_input): Step 1: ASR - 语音转文字(端到端模型) text = self.asr_model.transcribe(audio_input) WER < 5% Step 2: NLU - 意图识别 + 实体提取 intent, entities = self.nlu_model.parse(text) 意图识别准确率 90%+ Step 3: 上下文管理(支持12+轮对话关联) self.dialog_memory.append({"text": text, "intent": intent}) if len(self.dialog_memory) > 20: 记忆最近20轮 self.dialog_memory.pop(0) Step 4: 执行响应 return self.execute_intent(intent, entities, self.dialog_memory)
七、底层原理支撑
语音助手的底层技术支撑主要来自以下三个方面:
7.1 大语言模型(LLM)融合
2026年的主流趋势是将大语言模型与语音处理流水线深度融合。以130亿参数模型为例,在金融产品推荐场景中,可将对话轮次从传统方案的3-5轮提升至8-12轮,意图识别准确率提高27%-50。
7.2 端侧AI与隐私计算
Apple在其端侧AI方案中采用私有云计算(Private Cloud Compute, PCC)架构,所有个性化AI处理确保用户数据不出设备或仅经严格加密存储于隐私强化服务器-11。M系列和A系列芯片中NPU(神经网络引擎)算力的持续攀升,使得端侧大语言模型量化成为可能-16。
7.3 多模态交互
语音助手正从单一语音通道进化为融合语音、视觉、动作与执行能力的多模态全栈方案。例如,小米超级小爱的随心修图功能支持通过自然语言指令完成复杂的图片编辑操作-;Apple通过屏幕感知(Screen Awareness)实现跨App的复杂指令执行-16。
八、高频面试题与参考答案
面试题1:ASR与NLU的区别是什么?
参考答案:ASR(Automatic Speech Recognition,自动语音识别)负责将语音信号转换为文本,核心依赖声学模型与语言模型,输出是文本序列,词错率(WER)可低至3.2%。NLU(Natural Language Understanding,自然语言理解)负责从文本中提取意图与实体,基于Transformer架构,意图识别准确率可达90%以上。ASR解决“听清”问题,NLU解决“听懂”问题。
面试题2:语音助手如何处理多轮对话中的上下文?
参考答案:通过对话状态跟踪(Dialog State Tracking, DST)技术和记忆网络实现。基于Transformer架构的自注意力机制支持跨轮次对话关联,可支持12轮以上对话关联。在系统实现层面,通常维护一个对话历史缓冲区,每次输入时结合前序对话共同输入大模型进行推理,从而理解上下文依赖和话题切换。
面试题3:Transformer架构如何提升ASR的准确率?
参考答案:Transformer通过自注意力机制(Self-Attention)实现长距离依赖建模,消除了传统GMM-HMM框架中声学模型与语言模型的割裂训练问题。以Conformer模型为例,其结合了卷积模块和多头注意力,在LibriSpeech数据集上WER降至3.2%,相比传统方法显著提升了在噪声环境、口音适配等复杂场景下的识别效果。
面试题4:2026年语音助手的主流技术架构是什么?
参考答案:主流架构采用大模型与语音处理流水线深度融合的分层设计,包含音频采集→声学前端处理→ASR→NLU→对话管理→TTS六个核心环节。底层支撑包括基于Transformer的深度学习模型、端侧大语言模型量化、以及多模态交互能力。在部署形态上呈现云边端协同趋势,云端处理大参数模型推理,端侧实现低延迟响应与隐私保护。
九、结尾总结
本文围绕2026年4月10日五大常见AI语音助手的最新格局,从技术痛点切入,深度拆解了ASR与NLU两大核心技术概念,并以Siri、小爱同学、天猫精灵、豆包、Google Assistant为案例,分析了各厂商的技术演进路线。核心要点如下:
ASR负责语音→文字,依赖声学建模与语言建模,Transformer架构将词错率降至3.2%
NLU负责文字→意图,基于预训练大模型,意图识别准确率可达90%以上
对话管理维护上下文,支持12+轮多轮对话关联
底层支撑涵盖LLM融合、端侧AI隐私计算、多模态交互三大支柱
易错点提醒:初学者容易将ASR误认为语音助手的全部,实际上一套完整的语音助手系统是ASR + NLU + 对话管理 + TTS的有机组合,缺一不可。
下一篇预告:《语音合成(TTS)技术深度解析:从波形拼接到情感化表达》,欢迎持续关注!